Machine learning-ready data set
The machine learning-ready data set feature allows the export of data into a single data set, easing performance of advanced analysis with Optimize. The data set generated can contain process information and be assembled by generating a raw data report.
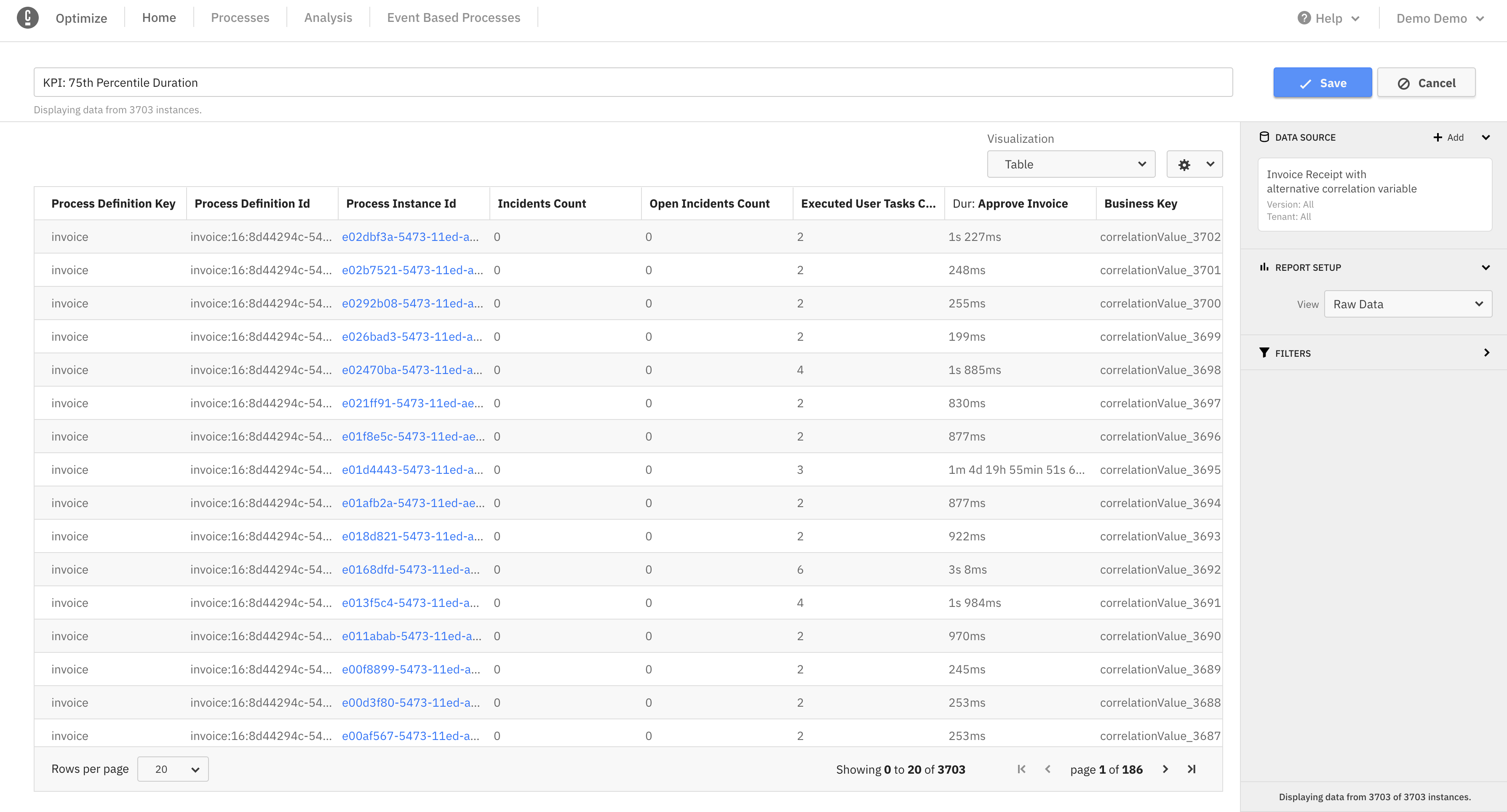
The data contained in the raw data reports is already organized and pre-processed in such a way that it would allow a trained model to make predictions for future instances based on existing instances for a given definition.
In addition to the previously existing columns in the raw data reports, we added columns for improved machine learning capabilities. These columns allow a user to access information such as the total number of incidents per process instance, the number of open incidents, the number of user tasks, and the total duration of an event.
For example, this allows you to predict how long an instance will take to complete based on the number of incidents or user tasks.
After navigating to a raw data report, note the added columns are now displayed:
In most cases, when training a machine learning model the data can be fed to common libraries, such as pandas or scikit-learn in CSV or JSON format. To export all data contained in a raw data report and use it as input for model training, export the raw data reports in JSON format.
This can be done after saving the report and utilizing the external Optimize endpoint provided to export it to JSON. More information on how to use the JSON export endpoint can be found here.